Intro to AI Security Part 2: what is AI and why is it vulnerable?
The tricky thing about using a term like ‘Artificial Intelligence’ is the implication that ‘intelligence’ is well defined.
We find it hard enough to define intelligence in humans let alone computers. I personally believe that it’s impossible to compare the kind of intelligence that makes some people good at maths to the kind of intelligence that helps others be charming in group settings.
Also, the media hype AI is receiving at the moment might lead people to believe that AI is a new thing, however it’s not. In fact, AI hype has gone through multiple cycles over the last hundred or so years.

The history of AI
Humans are lazy. (Anthropologists would rephrase this as ‘humans are distinctive for our ability to use tools to save human effort’). We can trace the concept of ‘artificial intelligence’ as far back as humans have tried to automate away things we would otherwise do ourselves.
Some early examples of this include the Antikythera mechanism, an astronomical calculator that was built in Greece around 100 BC to make astronomical predictions. Another is the Chinese abacus, which was invented in the 2nd century BC and is still used today.
The 18th century was the age of the automata, which were complicated (and often beautiful) mechanical instruments that were alternately useful or playful. French inventor Jacques de Vaucanson created a number of lifelike automata, including a duck that could eat and quack, and a flute player that could play music. In the 19th century, British mathematician Charles Babbage designed a mechanical computer called the Analytical Engine, which is considered to be the first computer.
The term ‘artificial intelligence’ dates back to 1956 and cybernetics researcher John McCarthy for the Dartmouth Conference (cybernetics is the science of control and communication in both machines and living organisms). He basically rebranded his work as ‘artificial intelligence’ to get more attention. Most key Machine Learning (ML) principles emerge around this time. The first machine learning model was invented by Arthur Samuel in 1959, a program that could learn to play checkers by playing against itself. In 1965 Skynet Minsky and Seymour Papert introduced the Perceptron, the first neural network model.

While the term ‘learning’ makes these machines sound very smart, much of this learning could also be interpreted as identifying patterns or trends, and making predictions, which mostly relies on being able to execute findings based on statistics. This is why many ML practitioners refer to it as ‘statistics on steroids’. Most of these models could not easily be implemented, because they relied on computational power that was not readily available at the time. These sorts of limitations have led to periods referred to as ‘AI winters’ — periods when interest and funding in AI research significantly declined due to both practical challenges like lack of foundational computing resources like hardware, memory and power, as well as general disenchantment with the term. The first AI winter occurred in the 1970s and 1980s, and a second AI winter followed in the late 1980s and early 1990s. During these periods, funding dwindled, research stagnated, and some AI projects were abandoned.
The most recent re-emergence of the AI field started in the late 2000s/early 2010s with the increasing access to compute power (like GPUs — graphical processing units) to conduct ‘deep learning’, and was bolstered by advances in deep learning methods like Transformer networks (which power large language models, like ChatGPT). Let’s take bets to see if we have another AI winter yet to come (and hope it comes after I retire).
How does Skynet (and other systems) use AI
Skynet’s AI brain is made up of many models, but in general all of them can be referred to as machine learning models. Machine learning involves algorithms that enable computers to learn from data and improve their performance over time.
Computer vision AI does just that — it helps computers to see. It aims to emulate human visual perception so computers can recognise objects, identify patterns, detect and track motion, understand scenes, and perform various tasks based on visual input. Computer vision is used in image and video analysis, facial recognition, object detection, augmented reality, autonomous vehicles, medical imaging, and surveillance systems.
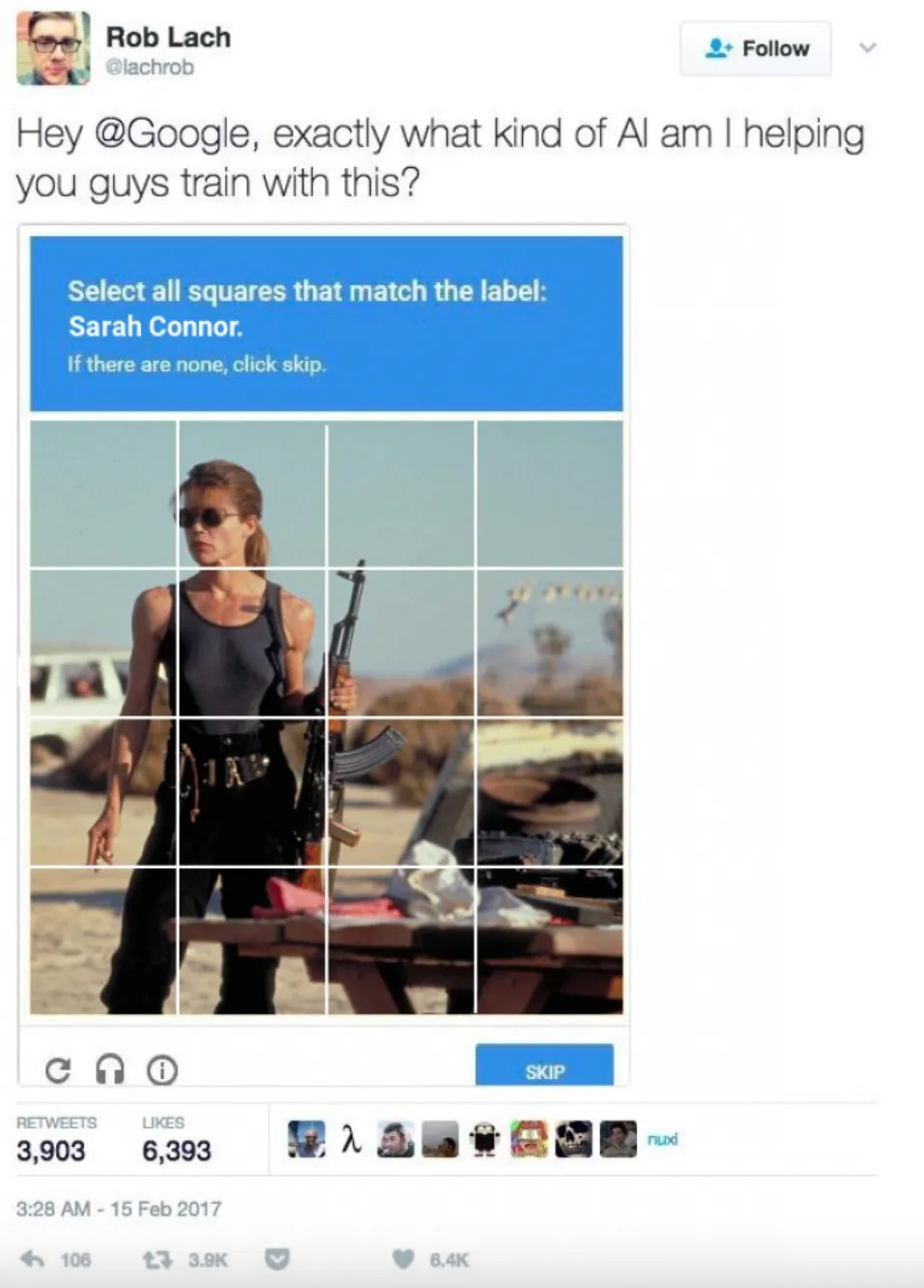
For example, to perform computer vision tasks like object detection and recognition (such as recognising Sarah Connor), Skynet might use artificial neural networks. Neural networks are a class of machine learning models inspired by the structure and function of the classic biological neural network — the human brain. The basic building block of a neural network is the artificial neuron, which processes and transforms input data, and then passes that data on to the next layer and so on until you get a probability or prediction out the other end. Deep Learning describes the characteristic ‘deep’ nature of machine learning models to use multiple layers of neurons. This is particularly good for extracting hierarchical features from data, and make it well-suited for tasks like image and speech recognition. These kinds of machine learning problems also tend to rely on supervised learning processes where you need to help the machine learn by labelling all the samples in your training data. This can be painful, expensive, boring work when you consider that training datasets often require many thousands of samples and not all of those will be pictures of cute cats (by the time you get to the thousandth cat you’d be pretty over it anyway).
Skynet also has Natural Language Processing (NLP) capability, which enables computers to understand, interpret, and generate human language. It’s used in language translation, sentiment analysis, and chatbots. Chatbots in particular are a popular topic today thanks to ChatGPT’s release last November. It is built upon a kind of ML model particularly suited for NLP tasks like those required by chatbots called the Transformer model. The Transformer model is a breakthrough architecture in the field of natural language processing (NLP) that revolutionised the way machines understand and generate human language. Prior to this model architecture’s release in 2017, getting models to understand what parts of text it needed to pay attention to was very challenging. You may remember some phones or computers had auto-complete functions, which often fell into repeating the same phrase over and over again. The Transformer model revolutionised language processing because part of its architecture includes units referred to as ‘attention heads’, which help the model remember things, understand context, and know what parts of a text it should pay attention to.
Another kind of machine learning technique is called reinforcement learning. This technique involves training AI agents to interact with an environment and learn through trial and error. It’s commonly used in training autonomous systems, gaming, and robotics. For example, when Skynet continues trying and failing to kill Sarah Connor or any of the other protagonists it learns from those experiences and improves (unfortunately). In fact, this is also how human children learn (fortunately).

We don’t always need ML in AI systems, and we can still often rely on basic algorithms or decision rules. These are simple rule-based systems that are able to execute processes that have clear rules, processes and pathways that a computer can follow — and don’t really require a machine to learn anything. Many games — chess, dominos, poker — are like this. They have pre-defined rules and procedures to follow. In business, robotic process automation refers to the application of computers to execute processes that might involve many applications but follow simple pathways (like long, boring but simple processes like opening a bank account, running a background check, moving files between folders).
We often refer to ML Robustness, which refers to the ability of an AI system to perform consistently and accurately across a variety of situations, including when faced with noisy or unexpected data inputs. A robust AI system should be resilient to changes, variations, or perturbations in its input data and maintain its performance without significant degradation. The opposite of robust AI is brittle AI.
There are some pretty grand claims these days about what AI can and can’t do, and how it’s the future. While I do work in AI, and I do love this work, I’m the first to say that AI is not nearly as powerful as the media reports it to be. This is due to many reasons — like companies making their AI capabilities seem better than they really are, or because some AI systems are great at some things but terrible at others. It is also because AI systems have specific concerns and vulnerabilities that are unique to the model building process, and this is my biggest concern.
Why is AI vulnerable?
AI systems are vulnerable to attacks in a way that other cyber and information systems aren’t, simply by virtue of the fact that they are inherently different types of systems. For example, AI systems contain different technical dependencies and methods to other systems, and these introduce different kinds of vulnerabilities and exploits to the system.
Cyber and information security professionals often use the example of a house to describe a system (the building) and its vulnerabilities (doors and windows where thieves, or hackers, can get in). Many people don’t realise that this analogy works pretty well for AI systems as well. AI systems are often referred to as black box in the sense that they have so many computations going on that it can be undecipherable to humans, but they are not mystical in the sense that all AI systems are built based on a specific known architecture. For example, convolutional neural networks are one kind of architecture, and Transformers are another. These architectures are like saying your house has a granny flat, or a treehouse, or a pool house. They are structures in their own right, that are added to your house, and add additional attack vectors (more windows, a dumbwaiter, a chimney, or a jealous neighbour). Computer systems with AI components increase the overall attack surface in unique and specific ways.
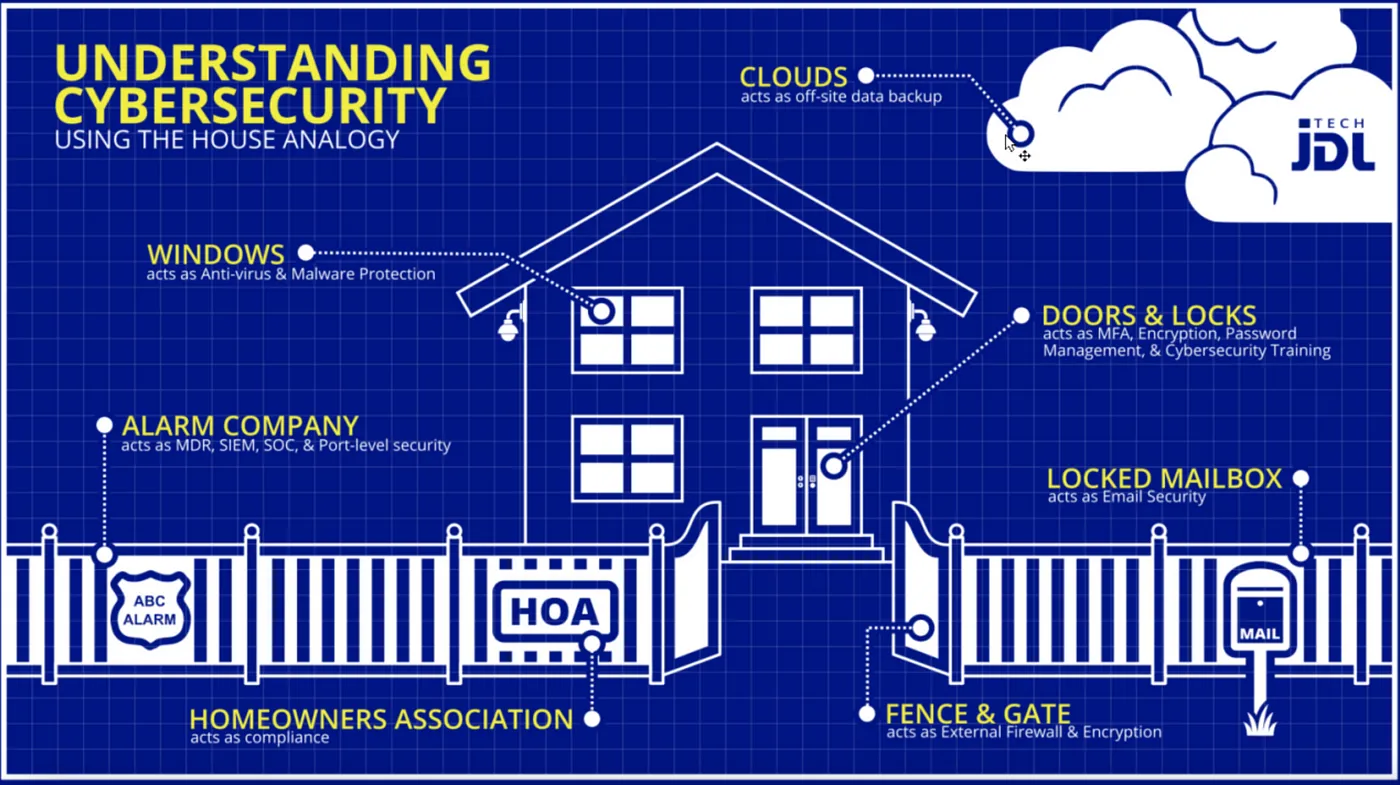
For example, AI systems have these additional considerations:
Data
Models are built to learn from input data, either to identify patterns or clusters, or to make predictions, as well as in downstream processes like fine-tuning and continuous improvement (periodically updating and retraining models). If the data is misrepresentative in some way, this will impact not just the model’s accuracy but also whether it might have learned ‘wrong’ things. Furthermore, there is research that hidden messages or relationships can be added to data that humans don’t notice, but can be learnt by models. This unintentional error is referred to as bias, and intentional error is known as data poisoning. Also, data changes over time and models should too (if the model no longer matches the data it’s meant to represent, this is called a distributional shift). Noisy data (data that doesn’t follow a neat pattern) is often very difficult to analyse, and we often refer to a ‘noise to signal ratio’ as describing how clear the data is at providing the information we’re looking for.
Models
Most people know that AI systems are dependent on models, but many people don’t realise just how many kinds of models there are, and how much the model selection not only impacts the accuracy and efficiency of a system’s predictions, but also what kind of vulnerabilities are introduced into a system. For example, some models can be very basic (think of a line of best fit from high school maths — that is technically a model), or very complicated (like the Transformer model that underpins ChatGPT). A regression model like our line of best fit has a simple formula expressed by: y = mx + b, which means it has two variables (m and b). However GPT-3 has 175 billion parameters, and its architecture (ie. the way these parameters are put together) is far more complex. Add on to this that models are complex networks of mathematical calculations that aren’t necessarily comprehensible to humans, and you have an extremely large and incomprehensible attack surface.
Interpretability
This refers to the extent to which AI systems are able to be interpreted or understood. It can be considered a sub-issue of model selection (ie. some models are easier to interpret than others) but also a system-wide issue when you have ensembles of many different models working together. This is particularly important when you have AI systems making important decisions (whether directly or indirectly), and could lead to issues with trust (either too much trust or not enough trust in the system). While cyber systems can be hard to understand, this is usually because they are not written in human-readable language and programs can be very long. However, peering into the mathematical nightmare of a model’s training process can be essentially impossible. A totally incomprehensible model is referred to as black box, but a model that is interpretable and explainable is referred to as white box.
Inputs and outputs
Models need inputs to be able to generate output. However the way that those inputs are crafted can impact the model’s results. Prompt engineering is an example of this — when humans give crafty results to chatbots to get back results that are otherwise not allowed by the chatbot’s manufacturer. For example, ChatGPT has controls to prevent it from giving back results that are harmful or dangerous (like instructing humans how to create a bomb), but if a human writes a suitably crafty response (like asking the model to pretend it’s for a movie plot) then the human can ‘jailbreak’ the model and force a response.
An example
Consider that Skynet’s computer vision model has been trained to perform facial recognition. This model has been trained on a dataset containing various people (one of whom is Sarah Connor). However, due to limitations in the training data and model architecture, it’s not robust enough to handle slight variations or adversarial inputs.
Now, an attacker crafts a carefully designed adversarial image by making minor changes to a legitimate image of Sarah. These changes are imperceptible to the human eye but are strategically crafted to confuse the model. When the model encounters this adversarial image, it confidently misclassifies her as Lara Croft instead of Sarah Connor, even though the image still clearly depicts Sarah. (This is a proverbial adversarial machine learning example by the way).
Another example of this I love is in the kids movie The Mitchells vs. the Machines — they have a pug called Monchi that can’t be confidently classified by these evil robots that are trying to take over the world. The robots think Monchi looks like a loaf of bread and — spoiler alert — the Mitchells are able to use this vulnerability to make the robots dysfunctional.

Now this is a great segue to the range of possible attacks that can be employed against AI — and the topic of the next blog.
See the accompanying video here: