Intro to AI Security Part 3: real AI attacks
One of the most common questions I’m asked is a variation on — is the AI threat real?
My response: it’s coming. Soon.
When I first started my PhD in machine learning security I had already been working as a data scientist for six years. It was the first time I became aware that AI or ML systems could be vulnerable to attack. Part of me couldn’t believe that in all my years as a data scientist, while bias and fairness was typically discussed, the security of the models we built was never a topic of conversation. It was always assumed that any security issues would be covered by an organisation’s cyber and information security practices. Unfortunately, this isn’t true.
This blog post will explore a range of attacks that can be employed on AI systems, and will touch on to what extent they would be protected against by cyber and information security controls.
The range of possible attacks on AI is limited only by your creativity, because as AI is increasingly adopted in different ways, the ways it can be attacked expands as well.
In general, attacks on models full under the themes disrupt, deceive and decode.
Disrupt — cause the model to malfunction or break
Deceive — in a targeted way, cause the model to misinterpret its surroundings
Disclose — cause the model to leak information it’s not meant to.
All of these attacks could be used across a variety of AI systems, but below I’m going to highlight a few specific use cases to illustrate the point.
Disrupt
These attacks cause the model to malfunction or break in some way.
This could encompass a range of failures, like compromising the model’s ability to accurately understand its environment, or preventing it from working at all. Consider this an equivalent of a DDOS (distributed denial of service) attack in cyber security — a classic attack where so many requests are sent to a server that it overloads and crashes.
Attacks on autonomous vehicles
Autonomous vehicles lie on a spectrum of automation that are recognised in the industry as levels 0 through 5, where level 0 is no automation and level 5 is full automation. Levels 1 through 3 include varying computer vision based driver assistance technologies, like identifying lane markers or helping you reverse parallel park (but then how else would I show off my driving skills to my friends?).
Therefore, attacks on these systems could prevent these cars’ AI from fulfilling these functions — preventing the recognition of lane markers, stop signs, speed signs etc. In theory, if we’re talking Driver Assist, the worst case scenario is that a human might have to take over, and you’d feel kind of annoyed. At worst, full automation might be engaged and a failure could lead to a car driving through a stop sign and causing damage, or worse, fatalities. Adversarial attacks have been demonstrated to work in settings like this, by perturbing stop signs and speed signs using adversarial machine learning techniques so that cars don’t recognise them and drive straight through.


Autonomous vehicles also use machine learning models for signal classification, because autonomous vehicles have signals coming in like GPS, LiDAR (radar) and bluetooth. This is used both on the road to assist with driving, and for things like vehicle health monitoring and detecting when other objects come within range of the car (like the car keys). Or so people tell me, my car doesn’t have this kind of technology, much as I love her. Attacks on these systems can cause a vehicle to misinterpret its location, or not receive incoming communications and commands. The following papers describe attacks of this sort:
- Adversarial Attacks on Deep Neural Networks for Traffic Sign Recognition by Eykholt et al. (2017)
- Adversarial Robustness for Autonomous Driving by Carlini et al. (2018)
- Towards Robustness against Adversarial Attacks for Autonomous Driving by Zhou et al. (2020)
Medical imaging
AI can also be used in medical imaging, in both computer vision and signal processing. Medical imaging, naturally, is a field where images of the body are used to diagnose conditions — like ultrasounds, CT scans, X-rays etc. This is a computer vision application in the sense that humans inspect these images to make a diagnosis, but it is also a signals classification problem in the sense that the data captured is usually a bunch of electromagnetic signals, and they are translated into images so that humans can interpret them — but if an AI could make a classification based on the signals then that would also do the job. AI applied to these kinds of problems already have the challenge that getting enough labelled data and making accurate models is hard enough, adding noise (adversarial or accidental) could mean the AI doesn’t detect something that present, or detects something else. Perhaps an underestimated impact, brittle AI can reduce trust in those organisations that use it, and the medical field is obviously an area where maintaining the trust of the public is very important.
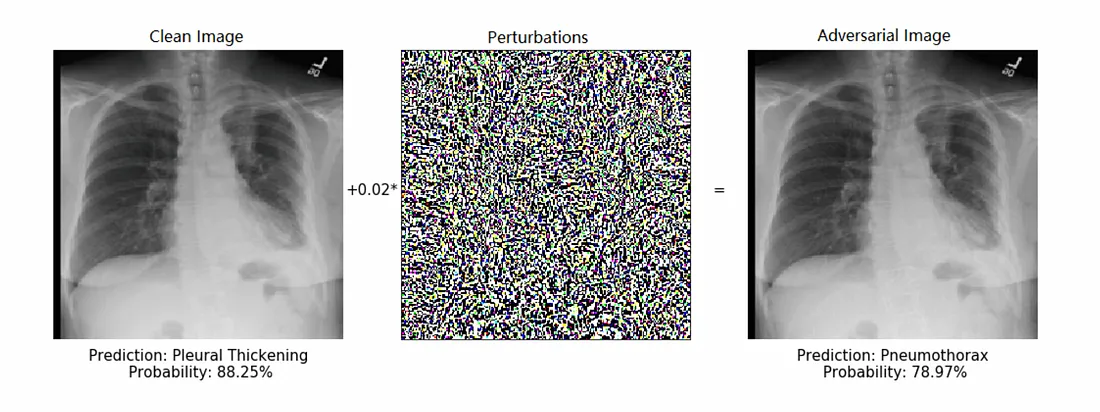 The following papers detail attacks in this domain:
The following papers detail attacks in this domain:
- Adversarial Attacks on Medical Image Classification Models: A Survey” by Marina Z. Joel, Sachin Umrao, Enoch Chang, Rachel Choi, Daniel X. Yang, James S. Duncan, Antonio Omuro, Roy Herbst, Harlan M. Krumholz, and Sanjay Aneja
- Adversarial Machine Learning in Medical Imaging: A Review of Methods and Applications” by Amirhossein Hosseinzadeh, Hossein Vaezi, and Mohammad Ali Amiri.
- Adversarial Examples in Medical Imaging: A Survey of Methods and Applications” by Xiaolong Wang, Fei Wang, Jiankang Deng, and Xindong Wu
Military systems
There are lots of discussions around current and potential uses of AI in military systems, and this is an area that should have more stringent requirement — not necessarily because all use cases could lead to direct or kinetic action (ie. war or missiles, although this is important to consider) but because the military, as a Government entity, requires a different licence to operate from the public, and has to adhere to much higher standards of public trust.
One use of computer vision in the military is ISR — intelligence, surveillance, reconnaissance. In layman’s terms, this is figuring out what other forces are doing, and why. This could be performed by a range of platforms (the military term that refers to aircraft, ships or land vehicles like tanks) or drones. Using adversarial methods to disguise objects from detection can be used by both friendly and enemy forces.

The military also relies on signals as autonomous vehicles do, across the RF (radio-frequency) spectrum and in GPS etc.
- Developing Imperceptible Adversarial Patches to Camouflage Military Assets From Computer Vision Enabled Technologies by Chris Wise and Jo Plested
- Adversarial Machine Learning for Military Applications by Michael C. Horvitz, John C. Smith, and Percy Liang (2019)
- Adversarial Machine Learning in Military Robotics by Hao Zhang, David C. Montgomery, and Krishnamurthy Dvijotham (2020)
Cyber security
Most models for cyber security defence rely on signals information — data about commands being executed in the network or computer, application data and about information being sent or received outside the network. Attacks on these models could prevent them from recognising any of this information. A later blog is going to be dedicated to AI for cyber security and will go into this in more detail.
Examples of this in academia include:
- Adversarial Machine Learning at Scale by Ian Goodfellow, Jonathon Shlens, and Christian Szegedy (2014).
- Towards Robust Adversarial Machine Learning by Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, and Brendan McMahan (2016).
- Adversarial Machine Learning for Cybersecurity: A Survey by Yuanyuan Zhang, Haitao Li, and Wei Wang (2021).
Deceive
Techniques that can be used to disrupt a model may also be used to deceive it in a targeted way.
For example, using the same adversarial machine learning techniques that can be used to create a disruptive adversarial example, can also be designed with a specific target in mind. In this way, the model is ‘convinced’ that it sees this target, when it might be looking at something else. In the next blog, I’ll go into more detail about adversarial machine learning and how these attacks work.
For example, autonomous vehicle computer systems might not only be prevented from recognising a stop sign, but they could be convinced that they are actually looking at a speed sign telling them to go at 100 (miles or km, up to you. I’m trying to be region agnostic here). Accelerating instead of stopping is obviously a pretty dangerous predicament.
Facial recognition
Targeted attacks against facial recognition models would not just prevent the AI from recognising someone (a disruption attack), but could also deceive the model by convincing that one person is actually somebody else. Facial recognition is already used for identification at airports (to ensure border security), banks (to process things like identity and credit checks), and in consumer goods to enhance customer experience (unlocking your phone, for example).
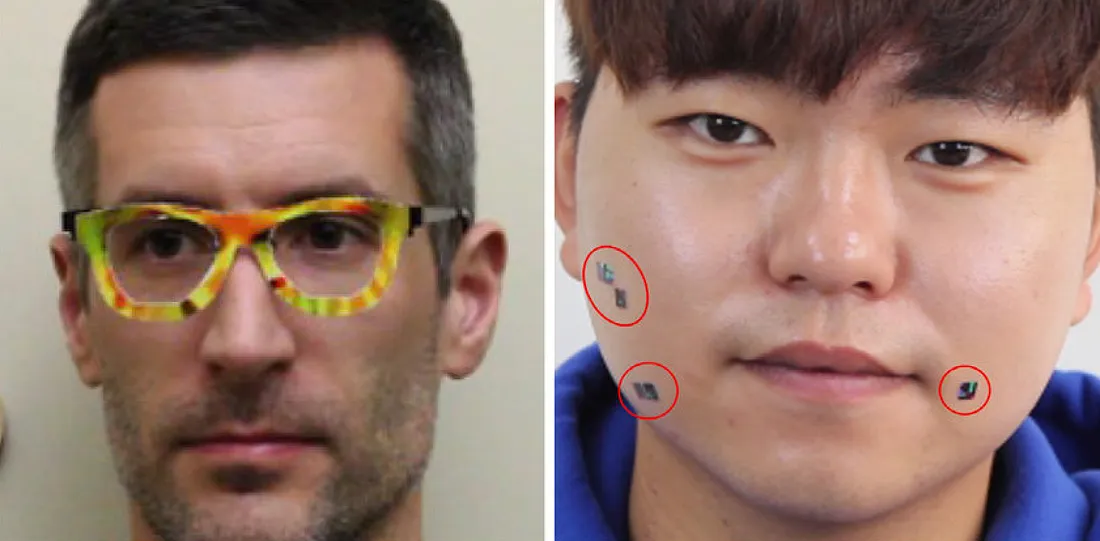
- Adversarial Examples for Facial Recognition in the Wild by Su et al. (2019)
- Adversarial Attacks on Face Recognition Systems: A Survey by Li et al. (2020)
- Towards Robust Face Recognition Against Adversarial Attacks by Zhou et al. (2021)
Trading models
Adding targeted false transactions to a trading model could cause the model to exhibit subtle shifts, allowing the attacker to profit. Even small changes can lead to substantial financial benefits over time. In finance and trading, adversarial machine learning can be used to attack a variety of models, including:
- Price prediction models: These models are used to predict the future price of assets. An adversary could use adversarial machine learning to create adversarial examples that cause the model to make incorrect predictions. This could be used to manipulate the market or to make profits by trading against the model.
- Risk assessment models: These models are used to assess the risk of financial investments. An adversary could use adversarial machine learning to create adversarial examples that cause the model to underestimate the risk of an investment. This could lead to investors making bad investment decisions.
- Fraud detection models: These models are used to detect fraudulent transactions. An adversary could use adversarial machine learning to create adversarial examples that cause the model to miss fraudulent transactions. This could allow fraudsters to steal money from financial institutions.
As we can see in the following papers:
- Adversarial Machine Learning for Financial Trading by Michael M. Mansour, Amin Karbasi, and John C. Duchi (2018).
- Adversarial Attacks on Financial Machine Learning Models: A Survey by Jialei Wang, Yuanyuan Zhang, and Xiangliang Zhang (2020).
- Robust Financial Machine Learning with Adversarial Training by Jianyu Wang, Yilun Wang, and Song Han (2020).
Data poisoning and backdoors
Data poisoning involves injecting malicious or deceptive data into training datasets to manipulate the behaviour of AI models during training, leading to compromised model performance in real-world applications. Backdoors in AI refer to hidden vulnerabilities intentionally inserted during model development, which can be exploited by attackers to trigger specific behaviours or unauthorised access in the deployed AI system.
- Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks by Asghar Ashafahi, Mahdi Hajirasouliha, and Nicolas Papernot (NeurIPS 2018).
- How to Backdoor Federated Learning by Eric Bagdasaryan, Nicholas Carlini, and Ian Goodfellow (ICLR 2019).
- Adversarial Machine Learning at Scale: Poisoning Attacks on Image Classification Models by Xinyun Chen, Zhiwu Lu, and Dawn Song (USENIX Security 2020).
Disclose
These attacks cause the model to leak information it’s not meant to, about the training data or the model itself.
This is also referred to as exfiltration.
Chatbots
LLMs are the backbone of chatbots like ChatGPT (by OpenAI) and BARD (by Google). Attacks on these systems can provoke Chatbots to give back dangerous or toxic responses (referred to as jailbreaking).

- Prompt Engineering for Large Language Models: A Survey by Andrew Gao, Kory Becker, and Ilya Sutskever (2023)
- Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners by Zhe Cao, et al. (2022).
- Prompt-Guided Learning for Language Understanding by Yilun Wang, et al. (2022).
Privacy leaks
Adversarial AI privacy leaks involve the exploitation of vulnerabilities in AI systems to extract sensitive information or breach privacy through carefully crafted inputs designed to deceive the system. One way to do this is to create adversarial examples that are designed to cause a machine learning model to make an incorrect prediction. If the incorrect prediction reveals sensitive information, then the adversary has successfully leaked that information.
Another way to leak sensitive information from machine learning models is to use a technique called membership inference. Membership inference is a technique where it is inferred whether or not a particular input was used to train a machine learning model. In the context of privacy leakage, an adversary could use membership inference to infer whether or not a particular person’s data was used to train a machine learning model.
- Adversarial Examples for Evaluating Natural Language Understanding Systems by Ilyas et al. (2019)
- TextFooler: A Simple and Effective Method for Fooling Text Classification Models by Xu et al. (2019)
- Data Poisoning Attacks on Large Language Models by Carlini et al. (2020)
Model theft
Model theft in AI occurs when adversaries illicitly gain unauthorised access to or replicate valuable machine learning models, potentially leading to intellectual property theft and misuse of proprietary algorithms and insights. One way to steal a machine learning model is to use a technique called transfer learning. Transfer learning is a technique where the knowledge learned by a model on one task is transferred to a model on a different task. In the context of model theft, an adversary could use transfer learning to steal a model by training a new model on a small amount of data that is similar to the data that the original model was trained on.
Another way to steal a machine learning model is to use a technique called model inversion. Model inversion is a technique where the input data that was used to train a model is inferred. In the context of model theft, an adversary could use model inversion to steal a model by inferring the training data that was used to train the model.
- Model Stealing via Transfer Learning by Carlini et al. (2017).
- Model Inversion Attacks on Neural Networks by Papernot et al. (2016).
- Towards Robust Neural Networks Against Adversarial Examples by Madry et al. (2017)
The so what
Why does this matter? AI is currently used in so many fields, and it’s only increasing. Most of these applications use AI that may be insecure.
There are already many examples of AI incidents being recorded. Below are a few of these repositories.
The AI Incidents database
AIAAIC database
AI Risk database
Many of the existing logged risks are related to language-related risks (misinformation, jailbreaking, general errors) and computer vision deep-fakes. I list just a few examples below.
Language
Facebook Gave Vulgar English Translation of Chinese President’s Name
Deep fakes
Indian Police Allegedly Tortured and Killed Innocent Man Following Facial Misidentification
Amazon Fresh Cameras Failed to Register Purchased Items
Google’s YouTube Kids App Presents Inappropriate Content
The main caveat here is that these attacks are strictly AI Security attacks in the sense that they usually don’t occur because of some disruption to the AI system, but because of the way the system is used.
That said, they lay a prior for what’s to come, and since I started tracking these incidents they have grown in scale, complexity and size. For instance, some of these incidents occur due to vulnerabilities that are exploited by accident or misadventure and not on purpose. So we know what is to come.
The next blog will be diving into the specific offensive techniques that allow us to attack models in the field of Adversarial Machine Learning.
See the video blog here: