Intro to AI Security Part 4: Adversarial Machine Learning
Now I’ve touched on Adversarial Machine Learning a few times already. However the actual techniques that underpin it are varied and deserve their own blog.
This one is going to get a bit math-y. But only a bit, don’t worry.
According to the Center for Security and Emerging Technology (CSET) at Georgetown University, there were 344,000 journal papers, books, book chapters and conference papers published on the topic of Artificial Intelligence (AI) in 2021 (the last year we have results from so far). This number speaks to the hype around AI technologies, for which Machine Learning (ML) is the main driver. It also speaks to not just the commercial interest in AI solutions, but the academic interest in novel capability, improvements and applications. While not all ML solutions will be as complex as GPT-4, by 2020 it was reported that some sort of AI had been productionised in every major industry across tasks like computer vision, natural language processing, classification and prediction.
This rapid adoption has spurred interest in techniques that could deceive, disrupt or hijack ML models, and this evolved into the field of Adversarial Machine Learning (AML). Interest in hacking or evading algorithms has existed since the 2000s, for example as means to evade malware classification or spam filters. However, designing methods that exploit inherent characteristics of ML architectures and characteristics, including but not limited to the loss function, training process, reliance on training data, weights, ‘black box’ nature, and different convolutional layers, is what distinguishes AML. Also according to CSET, there were 17,000 papers published on adversarial machine learning between 2010 and 2021. This may surprise you, especially if you haven’t heard of AML before.
AI Security refers to the technical and governance considerations that pertain to securing AI systems from disruption, deception and disclosure. Adversarial Machine Learning is the field that develops offensive and defensive techniques to attack models (although it does tend to focus on the offensive) and since it stems from the research community, it can have a more academic than practitioner leaning to it.
Szegedy et al. were the first to apply AML techniques to images in 2014, with Goodfellow’s 2015 paper extending it to create the Fast Gradient Sign Method (FGSM). They added specially crafted adversarial perturbations to an image to deceive image classifications in an untargeted or targeted fashion, which could not be detected by the naked eye.

Other image-based examples followed, including glasses that could evade facial recognition models, an adversarial sticker that could deceive person-detection classifiers, a 3-D printed turtle that convinces classifiers it is a rifle, even when rotated, and a sticker placed over a small segment of a stop sign that was instead interpreted by autonomous vehicles as a speed sign.

These methods have since been transferred to many other fields and input data types: banking, finance, social media, video (and deep fakes), network intrusion detection, healthcare, accounting, IoT, and communications. Improvements in the accuracy, dynamism and reactivity of these techniques, combined with a far less mature (and often non-existent) approach to ML defence and security, renders AML a burgeoning threat for all productionised ML models.
Since the explosion of Adversarial Machine Learning papers from 2014, the number of attack classes and subclasses have multiplied to over a hundred according to MITRE’s Adversarial Threat Landscape for Artificial-Intelligence Systems (ATLAS) knowledge base, which lists AML tactics, techniques, and case studies, as a complement to the ATT&CK framework for cyber security. There are even more if we include bespoke methods in academic papers. The Adversarial Robustness Toolbox (ART) is an open source Python library for machine learning security published by IBM, and the largest resource for AML methods and implementations.
Some maths
Ok here I have to include some maths but don’t worry, it’s only the necessary amount to be able to start a conversation about different AML methods without feeling like a loser.
Universal Adversarial Perturbations
The Universal Adversarial Perturbation (UAP) method adds a perturbation vector to an entire image that alters each pixel, for each image, by a unique value, but is not based on the loss function of the target model. The aim is that this vector be small enough to be unobserved by humans, but significant enough to fool the classifier.

This technique is basically a fancy way saying that we’re adding random noise with a bounded magnitude. Its success really exposes how brittle many ML models are.
The Fast Gradient Sign Method
The Fast Gradient Sign Method (FGSM) was first proposed by Szegedy and Goodfellow in 2014. This method calculates the gradient of the model’s loss function relative to the input. The attack is based on a one step gradient update along the direction of the gradient’s sign at each time stamp, clipped by the epsilon value.
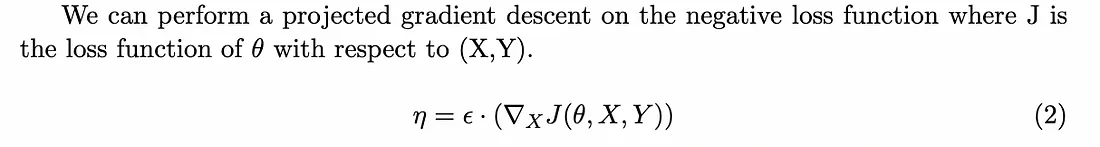 Its one-shot nature means it is computationally inexpensive but does not necessarily calculate the optimal perturbation vector. Despite its relative simplicity it has been effective against many target models.
Its one-shot nature means it is computationally inexpensive but does not necessarily calculate the optimal perturbation vector. Despite its relative simplicity it has been effective against many target models.
Projected Gradient Descent
Projected Gradient Descent (PGD) solves this limitation of FGSM by taking it a step further and instead of a one-step gradient update, takes an iterative approach. It calculates the loss with respect to the true classification over many iterations (t), still constrained by the epsilon value. This means it is more likely to find the perturbation vector with the global optimum.
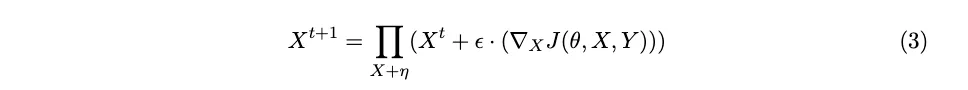 This method employs the L-infinity norm because it has access to the compute gradients across the entire image. This is a math-y way of saying that when ‘distances’ between the true and target value are calculated, it is done a specific way (to take the absolute value of the maximum). This is in contrast to the L-1 or L-2 norm, but don’t worry about those for now, just know at this stage that when talking to maths people they might refer to L-norms and they are basically referring to how the optimisation is performed.
This method employs the L-infinity norm because it has access to the compute gradients across the entire image. This is a math-y way of saying that when ‘distances’ between the true and target value are calculated, it is done a specific way (to take the absolute value of the maximum). This is in contrast to the L-1 or L-2 norm, but don’t worry about those for now, just know at this stage that when talking to maths people they might refer to L-norms and they are basically referring to how the optimisation is performed.
One Pixel Attack
The One Pixel Attack (OPA) also uses an iterative approach whereby it identifies a single pixel that, when perturbed, is most likely to cause the object to be misclassified. They convolve the original image with a single adversarial pixel perturbed to be some RGB colour, and identify the pixel location and colour that maximally perturbs the confidence for that image.
Adversarial Patch
The adversarial patch is an image which, placed near or on the target object, causes the classifier to ignore the item in the scene and report the chosen target of the patch.


Now there are many other techniques but I don’t have time to detail 95+ more. Go check them out here or here if you’re interested.
So I know there’s a bit of math here and that’s not for everyone, but if there’s anything you take away from this section it should be this: all of the techniques I describe mention the word optimisation.
Optimisation
In machine learning, optimisation refers to the process of finding the best parameters for a machine learning model. This is done by minimising a loss function, which is a measure of how well the model performs on a given dataset. There are many different optimisation algorithms that can be used to find the best parameters for a machine learning model. (Some of the most common algorithms include gradient descent, stochastic gradient descent, and Bayesian optimisation.)
Imagine a hill. The hill represents the loss function, and the goal is to find the lowest point on the hill, which represents the global minimum. The slope of the hill represents how quickly the loss function is changing. Optimisation algorithms can be thought of as walkers that are trying to find the lowest point on the hill. The walkers start at a random point on the hill and then take steps in the direction of the steepest descent. This means that they are always moving towards the lowest point on the hill.
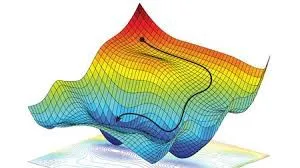
Many adversarial machine learning algorithms use the loss function but instead of moving down it (which makes the model parameters more optimised), it seeks to move up the loss function (and make the model less optimum, ideally in such a way that it causes a classification but does not move so far away that it is obvious to an observer). The process of ‘moving up’ the slope is akin to taking a mower or an earthmover (I’m clearly no expert in land clearing) to the hill and reshaping it so that not only is the path down the hill slightly different, but so is the rest of the hill (like updating pixels in an adversarial example image).
Attack surface taxonomy
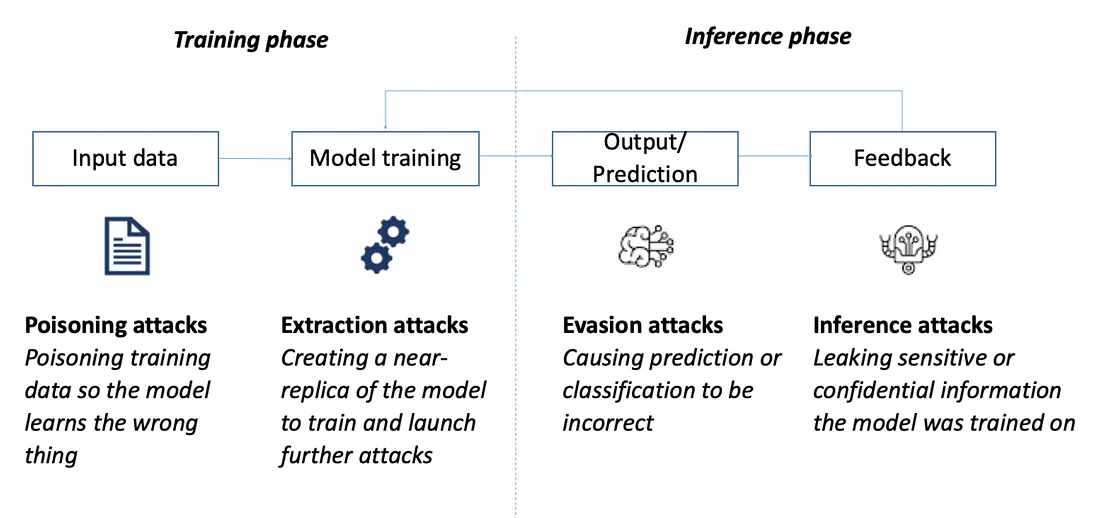
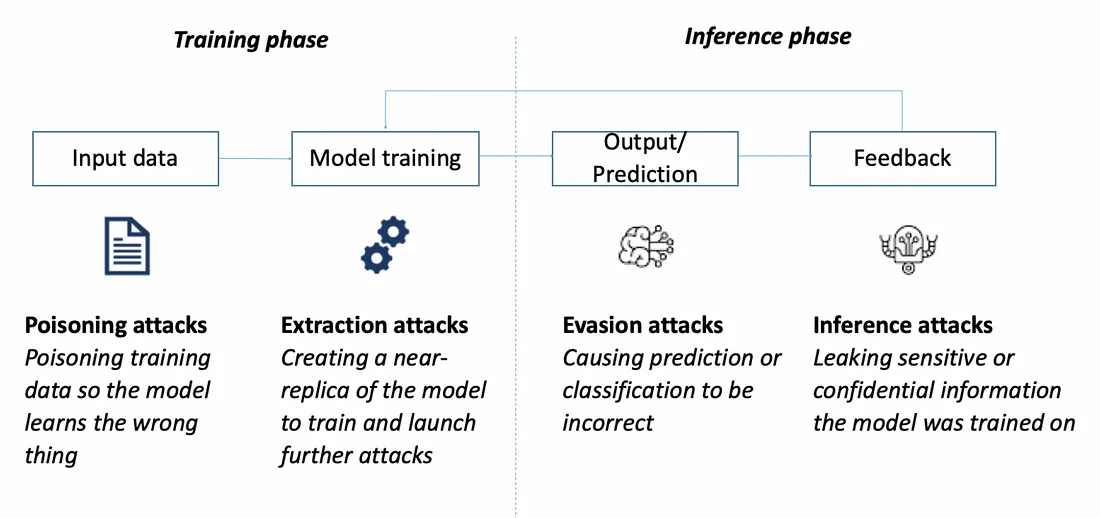
AML attacks can occur at every point in the ML Lifecycle, across training and inference. High-level attack classes include poisoning attacks, extraction attacks, evasion attacks and inference attacks. A systems-based approach to security should be considered as AI systems typically include many interacting ML and software systems.
AML attacks are further characterised by the adversary’s knowledge, specificity, attack frequency, and objective. The adversary’s knowledge of the target model is referred to as white, grey or black box. White-box presumes the attacker has full knowledge of the internal characteristics of the target model, which includes model weights, training data or loss function. On the other end of the spectrum, black-box necessitates no knowledge of the target model and is usually assumed to be the state of a real adversary. Grey-box refers to some point on the continuum between white and black box, where some of the characteristics of the target model is known. Attack specificity refers to what extent an adversary has a specific outcome in mind. A targeted attack directs the model to a predefined outcome. For example, adversarial perturbations that cause a classifier to predict a specific class. A non-targeted attack might aim to disrupt the model’s behaviour, but without an explicit outcome, such as adding random noise to an image that reduces its overall accuracy.
These characteristics, and the continuum for each, can be used for threat modelling to determine the impact of AML attacks on a target given contrasting adversary capability. Despite the multitude of attacks, there are many categories of ML that have yet to inspire attacks or be investigated for target or threat analysis.
Defences
In a future deep dive blog I’ll go into more depth on the range of defences, and how they can practically be employed. There are a number of defences that can be employed to mitigate the risk an AML attack will be successful against a system. Some are extensions of existing cyber security controls, however others are unique to the ML lifecycle and architecture of specific implementations. Cyber security controls that manage training data and constrain input data to the model reduce the risk of poisoning and extraction attacks. However the specific implementation of such controls may still leave open vulnerabilities, as recurring cyber incidents evidence.
Mitigations that are unique to AI Security include adversarial training, where a model is trained on those adversarial examples that might otherwise be successful at an evasion attack. However, this often comes at the expense of accuracy, a trade-off many organisations are unwilling to make (especially when accuracy is a proxy for profit). Adversarial training is also more effective on some use cases than others, for example it is very effective on computer vision but more challenging for other data types. Gradient obfuscation is another defensive method that mitigates against those white box attacks that rely on access to the target model’s gradient function. However, black box attacks against a surrogate model are often still extremely effective, especially since models trained on the same or similar data tend towards comparable internals. The defensive field is broad, with many other potential defences that focus on defence against specific attacks, or distributed approaches that spread risk.
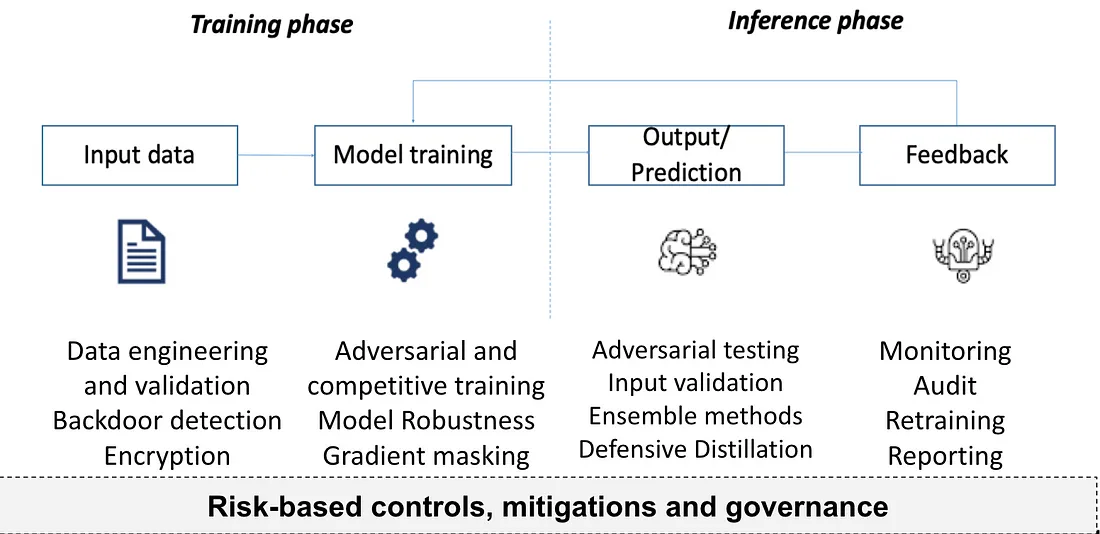
I would argue that the maturing of the AI Security field lies in moving the paradigm of attack versus defence to one of assurance and risk management. This is why, in discussing the security of an AI system, we focus less on the technical defences that could be put in place but rather on the needs of the ecosystem to enable and mature the practice of AI Security.
The current landscape is marked by an arms race that is emerging between adversarial machine learning techniques and model robustness. Unfortunately, robustness is often still an afterthought among the ML community. This is changing though, and I’ve been so delighted by the progress I’ve seen in the academic and practitioner community.
There’s still a long way to go, though.
The next blog will provide an introduction to cyber security, a field that has many contributions that can be offered to AI Security.